Thoughts on Large Language Models
2023-03-11 in misc
Epistemic status: I have no idea what I’m doing.
We’ve been discussing so-called “Large Language Models” (LLMs) during our past few gatherings in the local hackerspace. None of us are ML experts, but we’re all experienced professionals (mostly in software engineering of various kinds), and have diverse enough backgrounds for it to be interesting.
I wanted to jot some of the resulting thoughts down for posterity. I have no way of attributing these to any particular person as the discussions were… lively, but all of it has gone through yours truly thus it’s certainly plagued by my own misunderstanding and misconstruction. Nonetheless, it might be interesting to revisit them in a few years’ time.
The Ugly
The interesting part is that none of us seemed to be worried about the short- and medium-term prospects of AGI (artificial general intelligence). Personally, this is equal parts due to my scepticism on “strong” AGI in general, and a lack of belief that society will live long enough to achieve AGI. In addition, I always feel uneasy discussing AGI as I find it to be an ill-defined topic: we’re not really sure what “intelligence” and “consciousness” are when it comes to humans, and attributing such properties to computer programs seems odd.
There also seems to be a consensus that the LLMs we currently have are dangerous enough, and that the “AGI scaremongers” aren’t doing much about it. I always thought it’s interesting how the loudest and most paranoid folks sit on boards of companies and “think-tanks” most likely to end up actually producing AGI. My dudes1: if you’re so freaked out by the prospects of what you’re doing, simply… stop?
The argument here seems to be “if we don’t do it, someone else will”. This one’s kinda hard to refute, but here’s where I like to remind myself that the acronym for “mutually assured destruction” is “MAD”, and I can’t imagine that to be a coincidence. There’s some prior art here, and it’s not necessarily working in our favour.
The most immediate thing everyone’s worried about is the ability to generate a huge amount of very convincing text that has little to do with reality… a.k.a. complete and utter bullshit. Sure, OpenAI has these huge filtering layers that try to prevent the most disgusting of the options. These are… not perfect, and they mostly deal with the gory aspects of humanity. When it’s not trying to convince you that your obvious attempts at racial profiling are morally wrong, it’s still full of crap.
As a very benign example, my own attempts at using ChatGPT to clarify certain aspects of my quantum computing class weren’t great. I tried to see if it’d be able to argue whether a Toffoli gate is a valid oracle for the Deutsch-Jozsa algorithm2:
First, it claimed it’s not a valid oracle because it maps two input qubits to one output qubit rather than n qubits to one output qubit, which is silly as n=2 is a perfectly valid scenario.
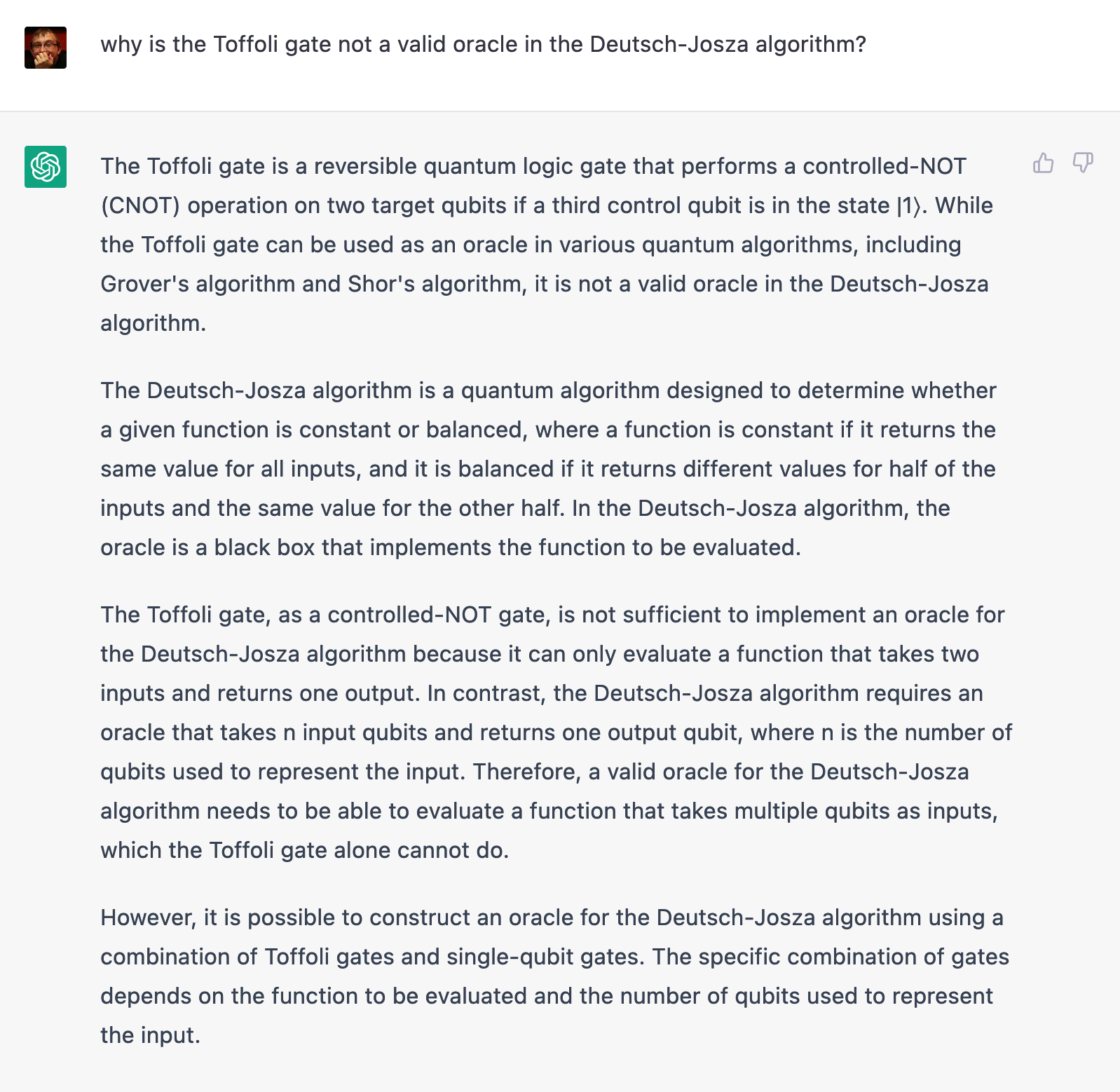
As a follow-up, I asked whether it’s a valid oracle in case where I only have two qubits as inputs, and it claimed it was.

I wasn’t convinced, though: with the target qubit set to |1> as in the Deutsch-Jozsa circuit, the Toffoli gate doesn’t seem to represent a balanced or constant function, which is a requirement for the oracle…
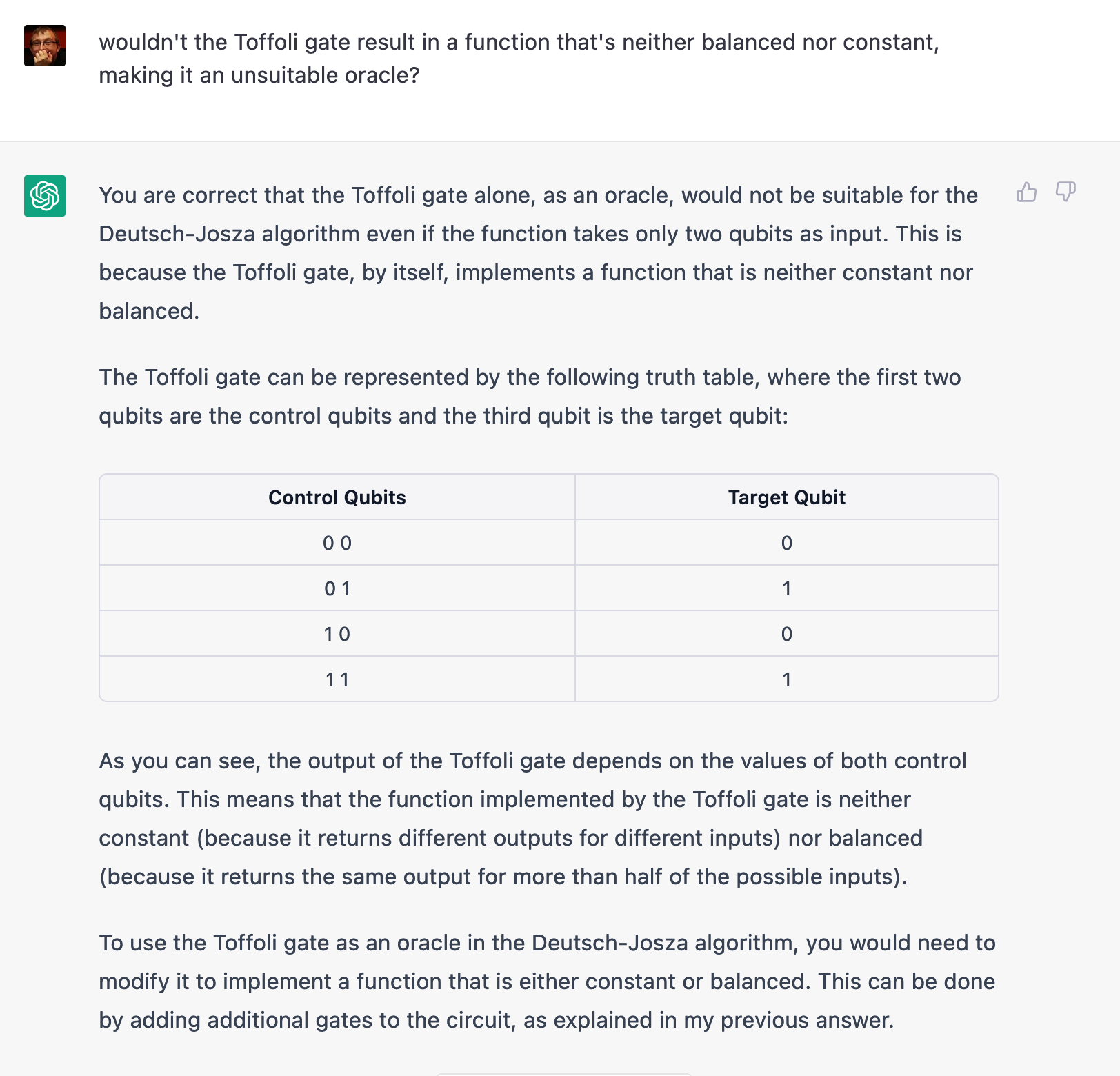
That truth table simply isn’t correct. At this point, I decided there really is no alternative to shutting up and calculating.
The Bad
Setting aside deeper existential concerns, there’s a different set of more prosaic issues that pop up.
It’s impossible to reproduce ChatGPT. The resources required for running LLMs are immense, and the resources needed to train them more-so — assuming you’re able to get your hands on the training corpus. Even if this ends up being the most benign and useful tool in the history of mankind, we’ll end up in the same place we always seem to do — with the means of production concentrated in the hands of the rich few. Sounds vaguely familiar.
Another issue is the “lack of traceability”. LLMs regurgitate things found in their corpus, which isn’t completely unreasonable, as that’s what they’re designed to do (ish?). However, there seems to be no way of programming these networks to actually attribute this regurgitation to its sources. Fighting bullshit is far simpler if the bullshitter quotes their sources (which, I guess, is why they rarely do), and avoiding plagiarism is far easier if you provide proper references. The level of granularity of LLMs probably makes this extremely difficult, and that’s not great.
The (Possibly?) Good
Now the good part: there seems to be some merit to it all. As a writing dilettante, I found the intra-textual stylistic coherence to be one of the more interesting parts of both GPT-3 and ChatGPT. Limiting my unsubstantiated claims exclusively to the English language, I feel like text generated by these models is more stylistically uniform than what ends up being produced by most non-professional writers.
I can imagine these systems being used by domain experts to write large amounts of text: prompt ChatGPT, sift through the bullshit, counter-prompt a few corrections & refinements, and finally edit the text to remove factual errors. It might not save any time compared to writing from scratch, but the end result might be better (for certain definitions of “better”). Finally, analyzing the resulting text could be a good exercise, the end goal being to become a better writer sans GPT3.
The conversational aspect of these models shouldn’t be underestimated either. Us hacker folks have spent most of our lives “prompt engineering” our machines in different ways — the idiosyncrasies of these systems are so ingrained into our brains we simply fail to imagine someone having trouble interacting with them. These failures happen regularly, though, and interacting with the machine in natural language is very attractive. Instead of adding quotes or minus signs or “site:reddit.com” to your search query, you can ask the machine to refine its output in your spoken language of choice.
That is powerful, and that is appealing. We need to make sure people understand there’s still a machine behind the output, together with all implications of this fact. I’m not sure whether we’re doing a very good job at the moment, and there be dragons. A good, approachable paper on this topic well-worth a read is M. Shanahan’s “Talking About Large Language Models”.
On a bit more science fiction-y note, there’s the very interesting question of what these models really are. People managed to train something GPT-like to play Othello, and the model seems to have inferred certain properties of the game4. Is this pure statistical symbol manipulation? Is it something more? Is there a difference? It’s fascinating to think about, and it’ll be fun to see if it produces some good science and/or philosophy.
I’m trying to wrap this up on a positive note, although the obvious position is defeatist. There’s many, many more things to consider here, yet we keep on keeping on without proper evaluation. I’m hoping we’ll be seeing much more good science and philosophy than well-written misinformation and terawatts of electricity flushed down the toilet, but this century doesn’t give too much material to cling to. Here’s to being alive and well enough to see the outcome.
Interestingly enough, it’s always dudes, isn’t it?
This is just another example where it’s almost critical for the user of the LLM to be a domain expert when using it in a research capacity. I had no illusions of the results being infallible so I triple-checked, but I might as well have taken it at face value.
Of course, you can totally do that without LLMs — by reading and analyzing text written by good writers. However, within highly specialized niches, it might not be obvious who these good writers are.
This is a preprint, and I’m not sure whether it’s been verified or reproduced — even if it has, I wouldn’t really be able to tell.